The platform is built around two interchangeable voice runtime architectures.
Realtime mode delegates the entire conversation loop to a single speech-to-speech provider such as OpenAI Realtime, xAI Grok, Google Gemini, Alibaba Qwen, or Amazon Nova Sonic.
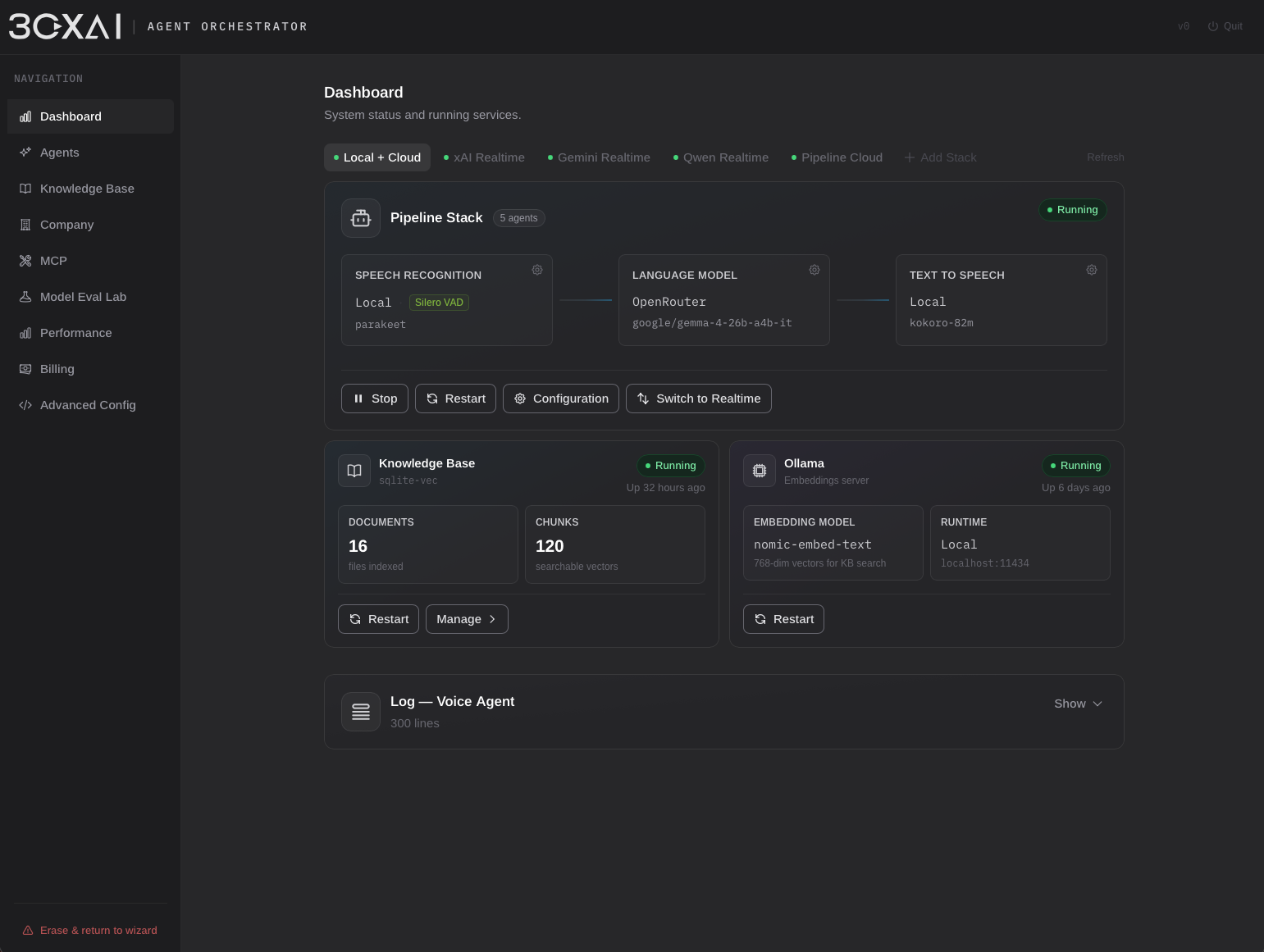
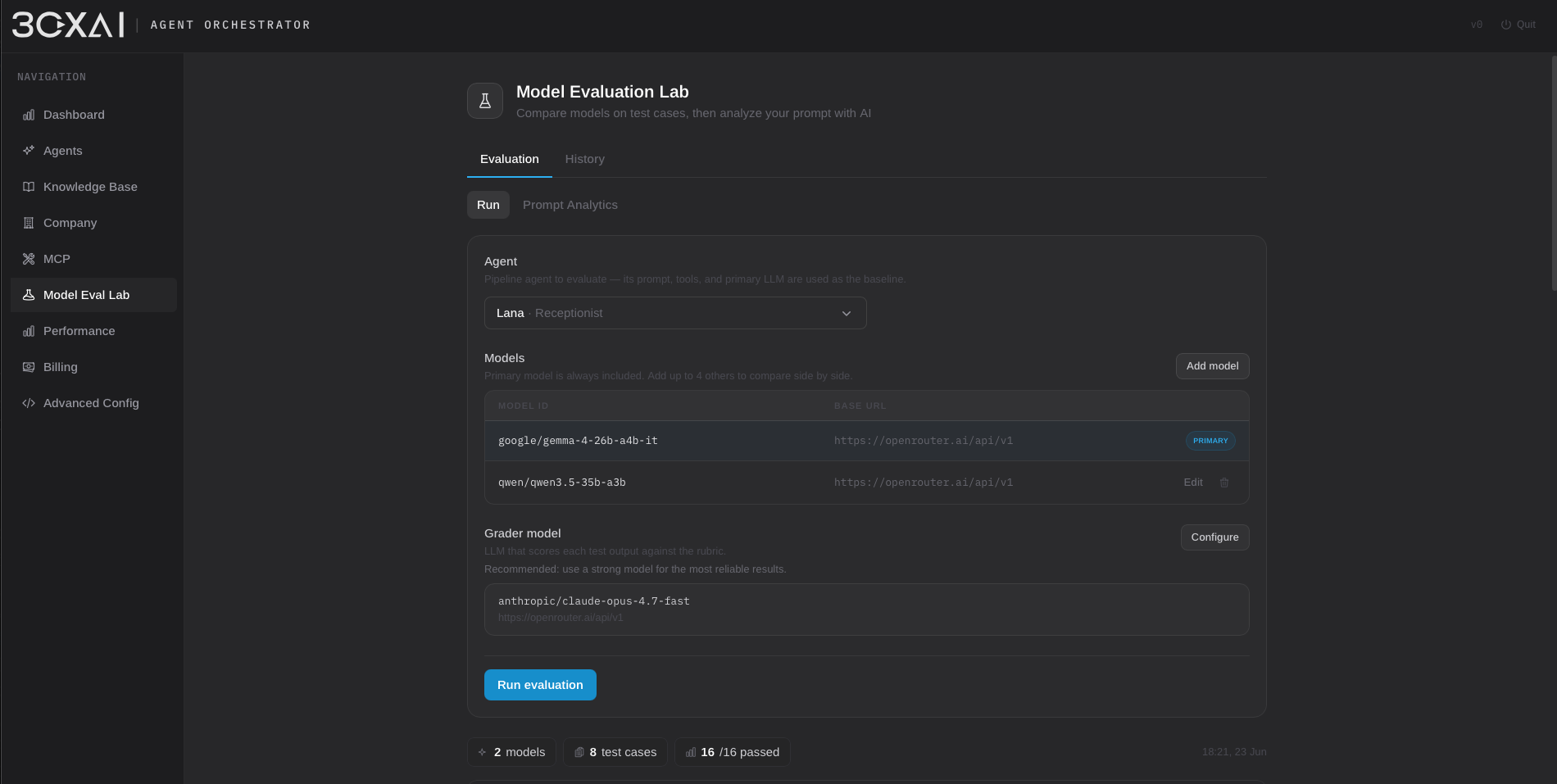
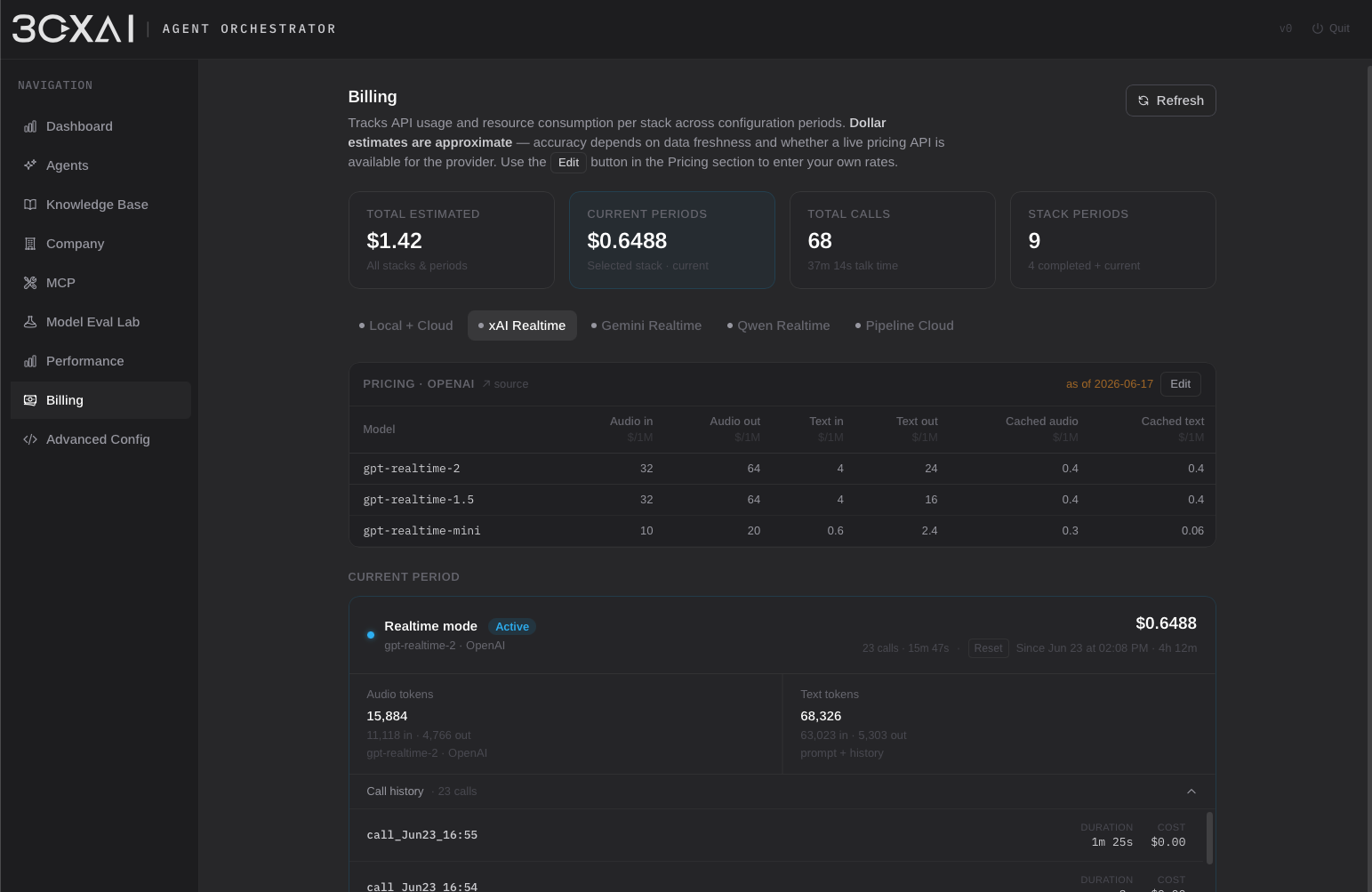
Pipeline mode decomposes the conversation into independent STT → LLM → TTS stages. Each component can be configured separately and deployed either through cloud providers or self-hosted services. Cloud deployments support OpenAI-compatible providers such as OpenRouter, TogetherAI, Hugging Face, Grok, and others, while local deployments can be powered by Ollama, custom Python services, or any endpoint exposing an OpenAI-compatible interface. Hybrid architectures are fully supported — for example, local speech processing combined with a cloud-hosted reasoning model.
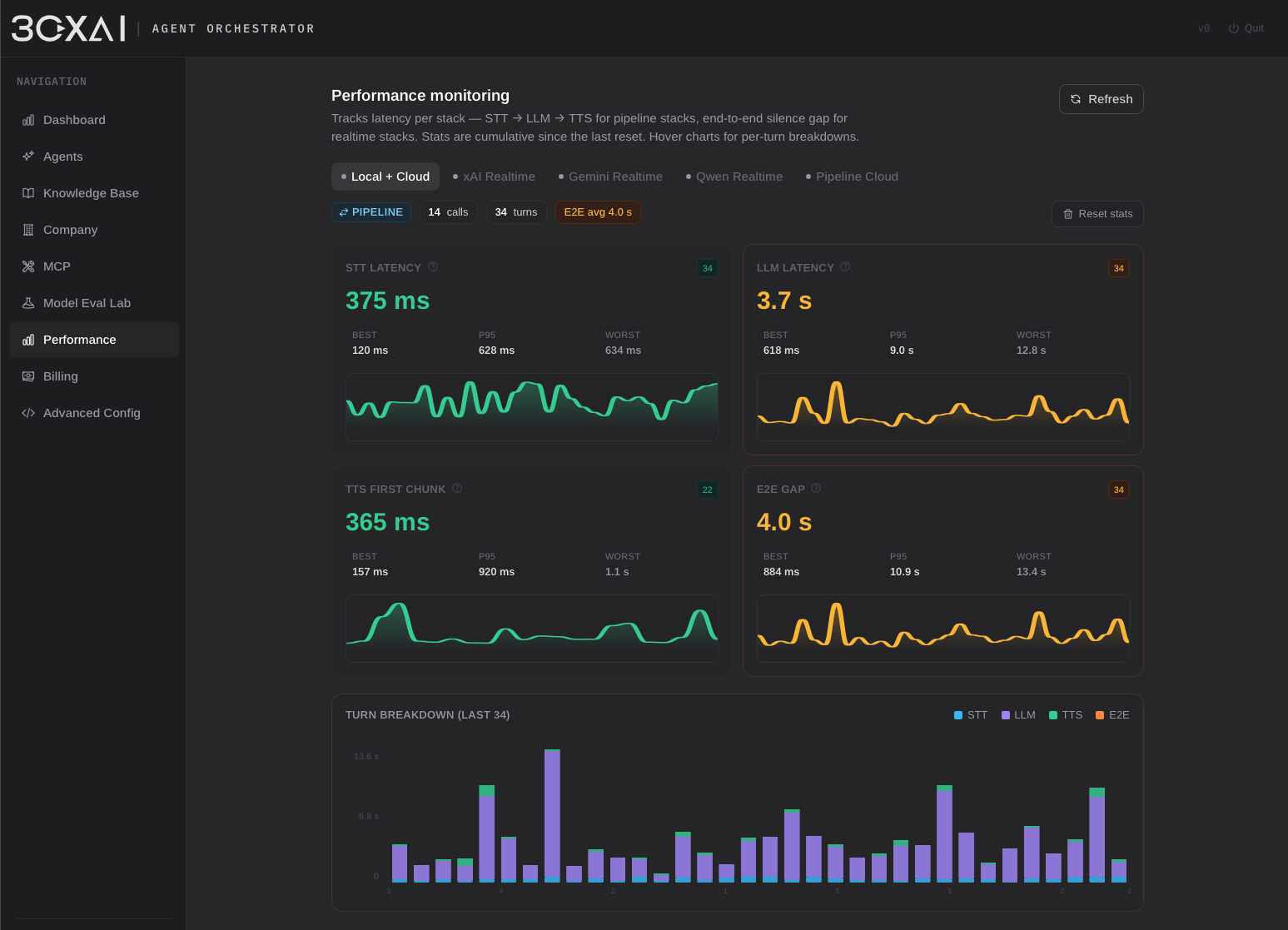
To maximize provider compatibility, the pipeline runtime is built around OpenAI-compatible APIs and implements a pseudo-streaming layer on top of traditionally non-streaming speech services. This allows a broad range of cloud and self-hosted STT/TTS solutions to participate in near real-time conversations while maintaining a unified integration model.
The voice stack can be enhanced through optional processing modules. Currently the platform supports neural Voice Activity Detection using Silero VAD (ONNX Runtime) as an alternative to traditional amplitude-based detection, improving speech segmentation, interruption handling, and transcription quality. Because audio processing is implemented as an independent layer, additional services can be introduced without affecting the surrounding runtime architecture.
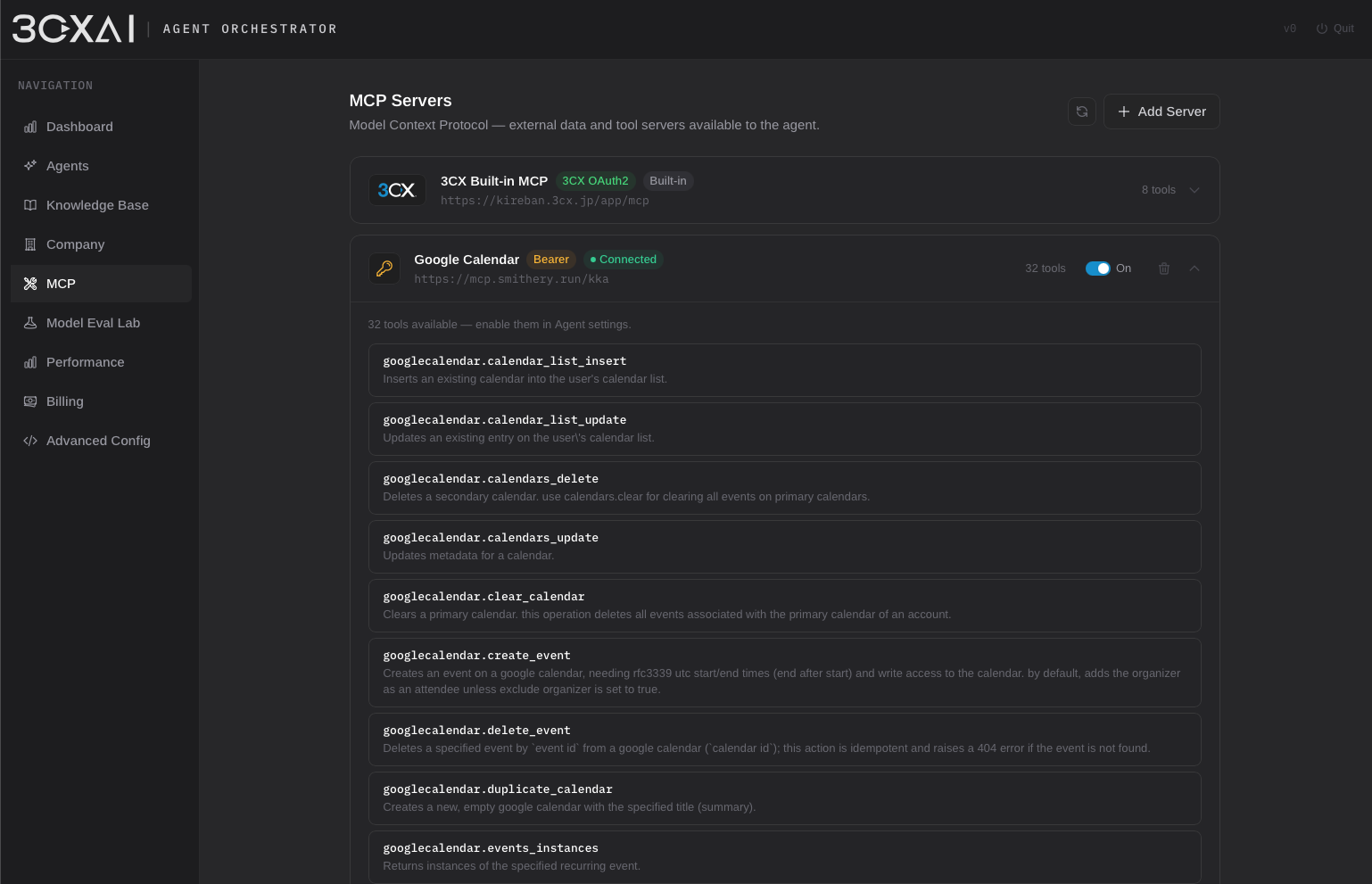
The platform integrates with 3CX through the Call Control API for real-time call handling and uses the built-in 3CX MCP server as its primary tool execution layer. Core capabilities such as contact lookup, extension discovery, call transfers, and routing are exposed to agents through MCP tools. Phonebook searches benefit from 3CX's fuzzy linguistic matching capabilities, helping compensate for speech recognition inaccuracies during voice interactions.
Native streaming support is planned for a future release as an alternative execution path alongside the current OpenAI-compatible pipeline. This will enable direct integration with streaming-first providers and self-hosted services while preserving the same runtime abstraction and agent configuration model.