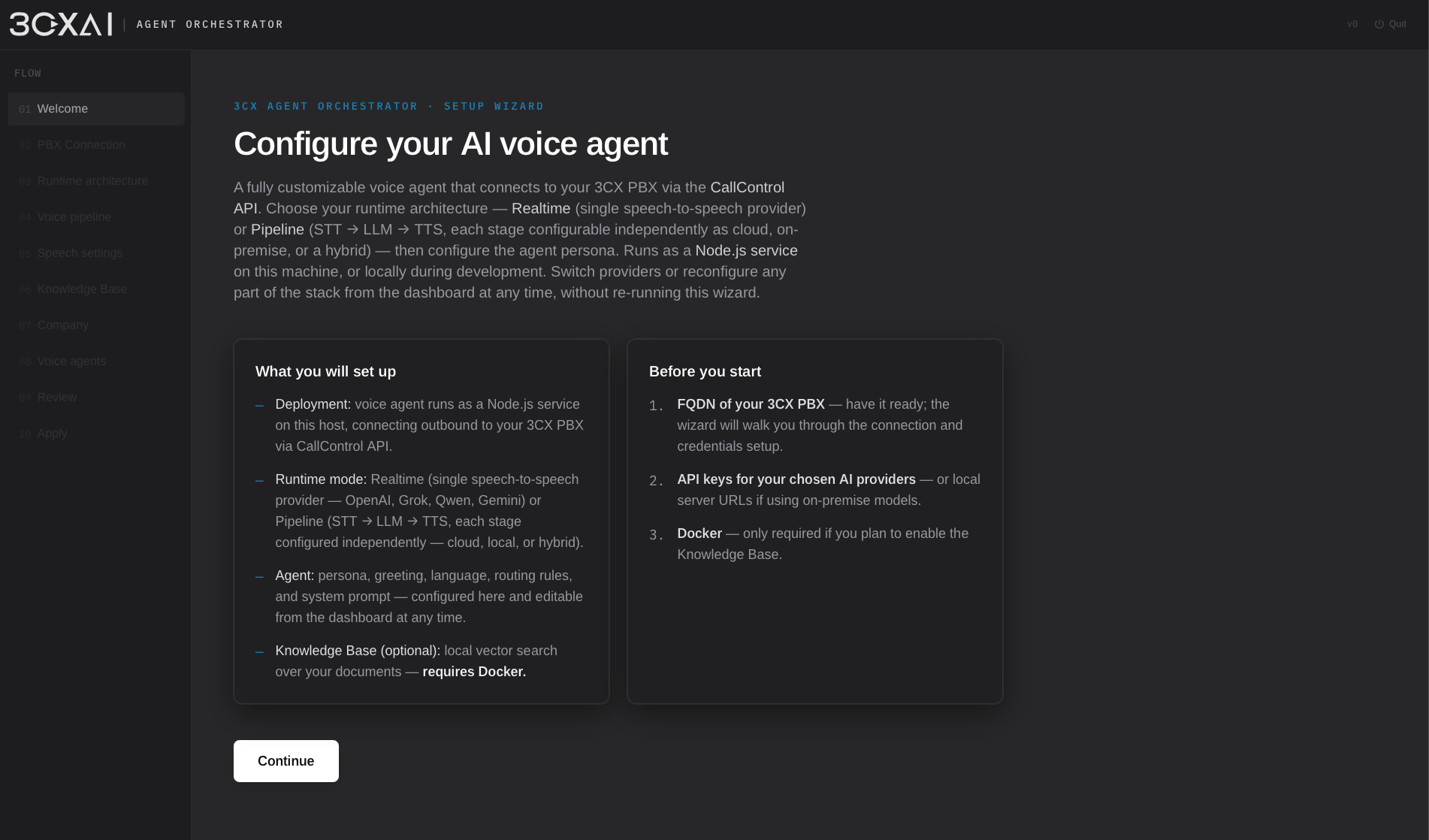
Onboarding Wizard
- 引导式 onboarding:从安装到首个已部署 agent。
- 配置 Realtime 或 Pipeline voice 架构。
- 连接云端或 self-hosted AI provider。
- 可选本地 Knowledge Base 部署(SQLite-Vec + Embeddings)。
- Agent 模板、routing、prompts 与 voice 配置。
- Onboarding 后所有设置仍可独立调整。
项目
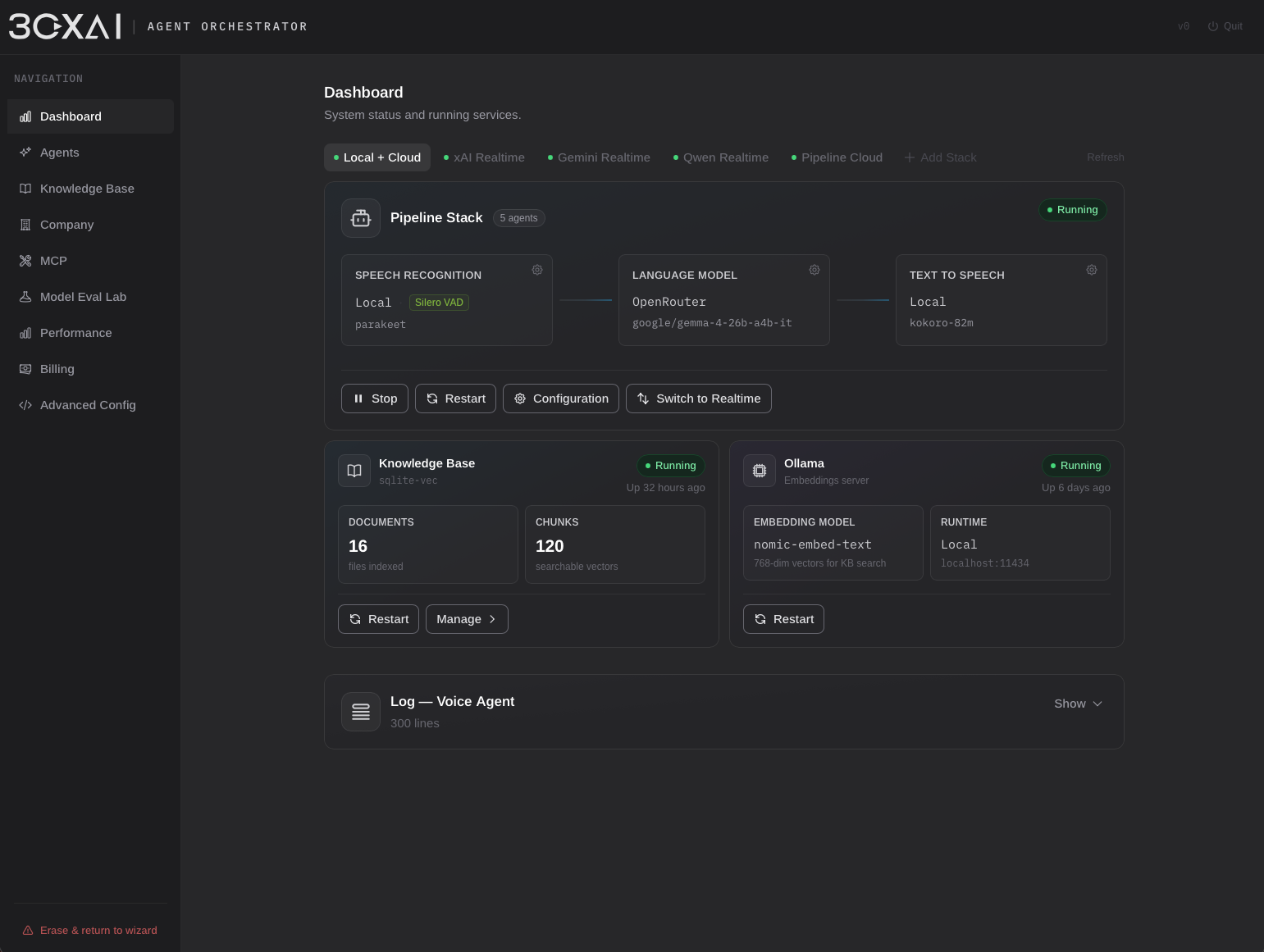
Voice Agent
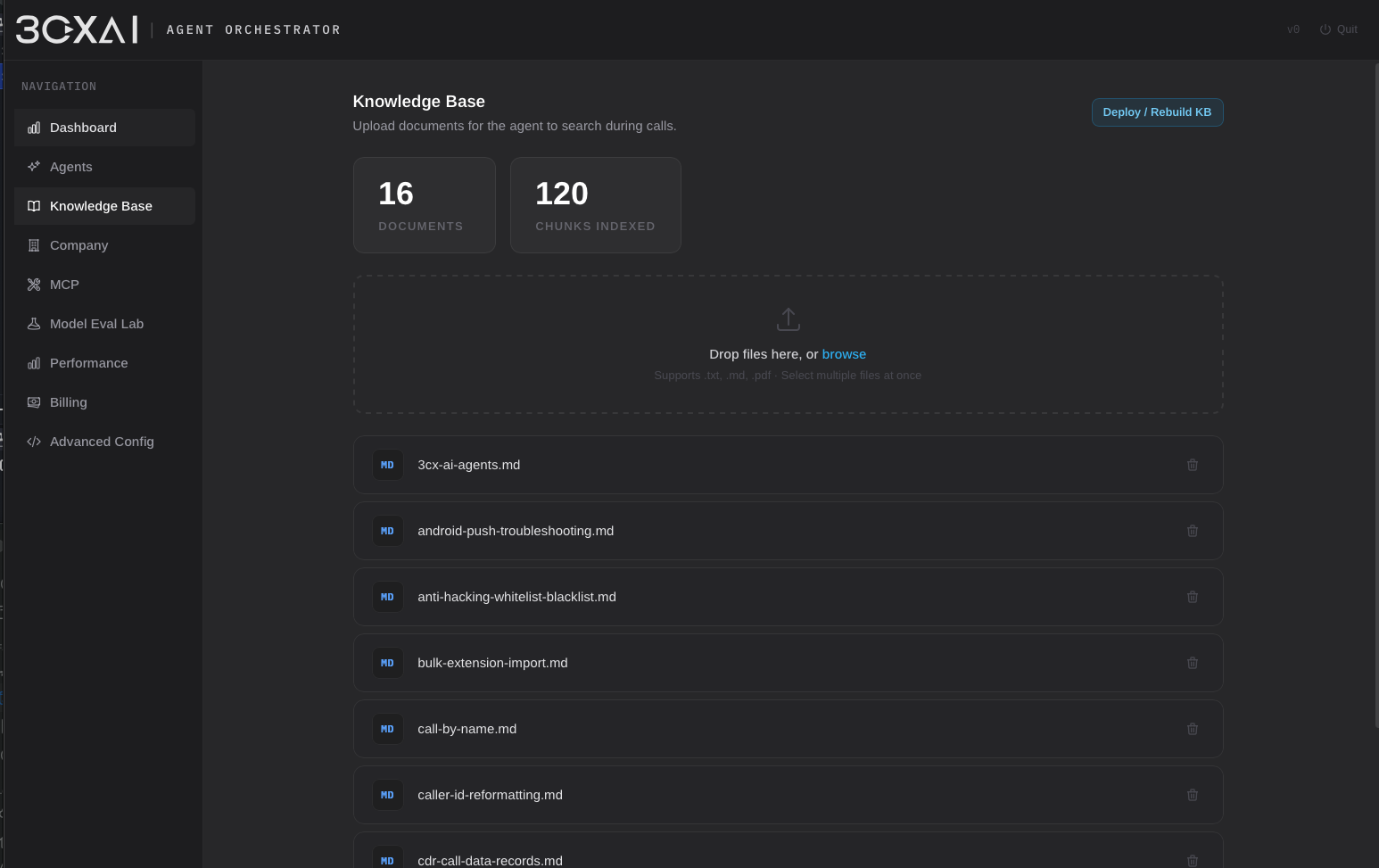
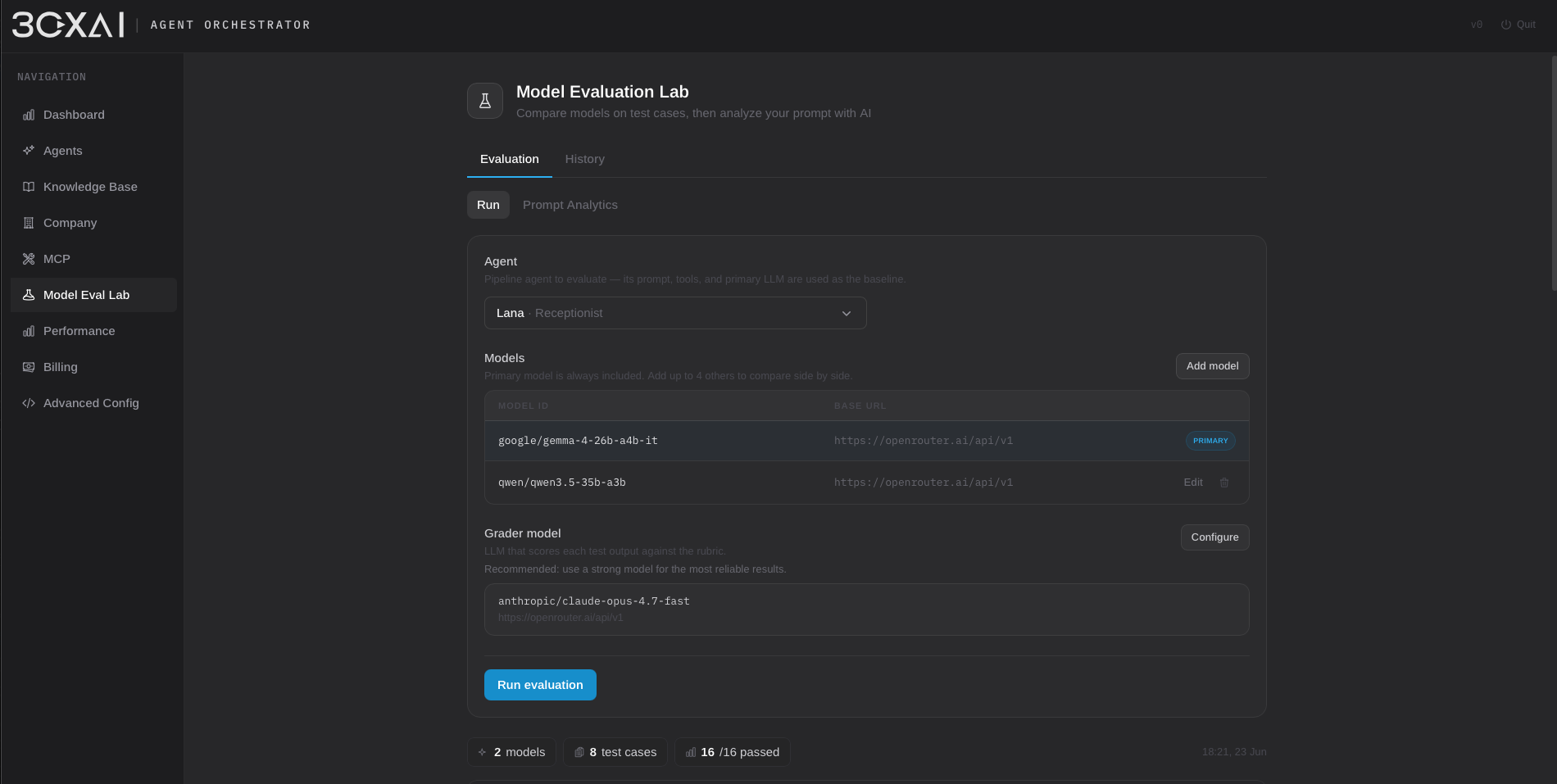
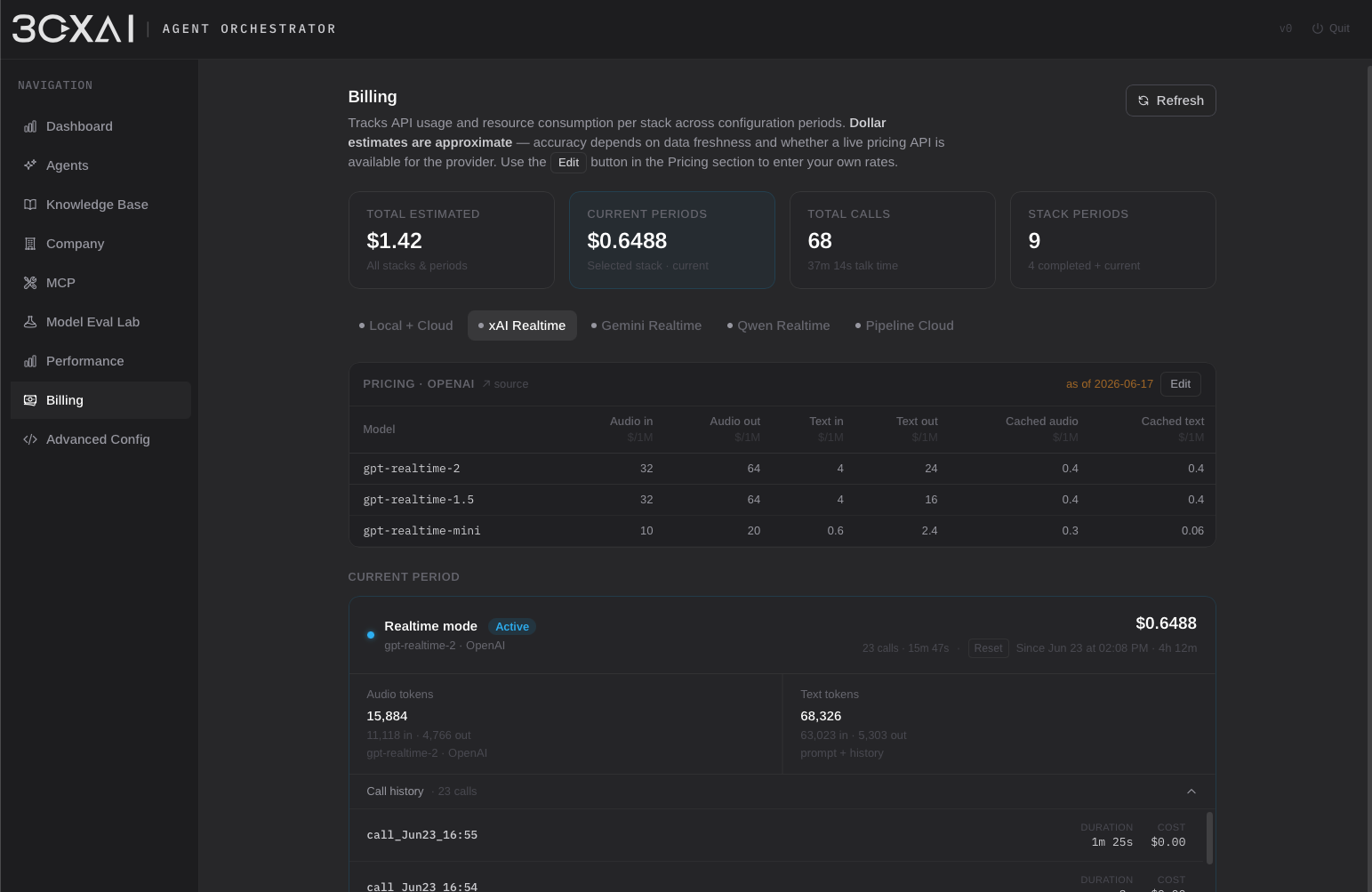
Voice Agent Orchestrator 是独立的 on-premises 平台,用于构建、评估和运行 telephony 场景的 AI voice agent。支持 realtime speech-to-speech 模型、模块化 STT→LLM→TTS pipeline、知识检索,以及基于本地与云端任意组合的 AI 驱动呼叫自动化。
平台有意与 PBX 解耦,作为独立 runtime 部署。这使 AI 基础设施 — 包括本地模型、向量数据库、embedding 服务与 evaluation 工具 — 可以独立于通信系统演进和扩展,同时保持 telephony 集成简单且 vendor-independent。
Voice AI 集成往往围绕特定 provider、runtime 和部署假设构建。当组织引入新模型、本地推理、知识系统或混合架构时,业务逻辑与实现细节之间的耦合越来越深。
结果是实验变慢、集成重复,且底层 AI 栈每次变化都会推高维护成本。挑战不在于支持单一 provider 或模型,而在于让对话系统能够演进,而不迫使周边平台随之一起演进。
平台围绕两种可互换的 voice runtime 架构构建。
Realtime mode 将整个对话循环委托给单一 speech-to-speech provider,例如 OpenAI Realtime、xAI Grok、Google Gemini、Alibaba Qwen 或 Amazon Nova Sonic。
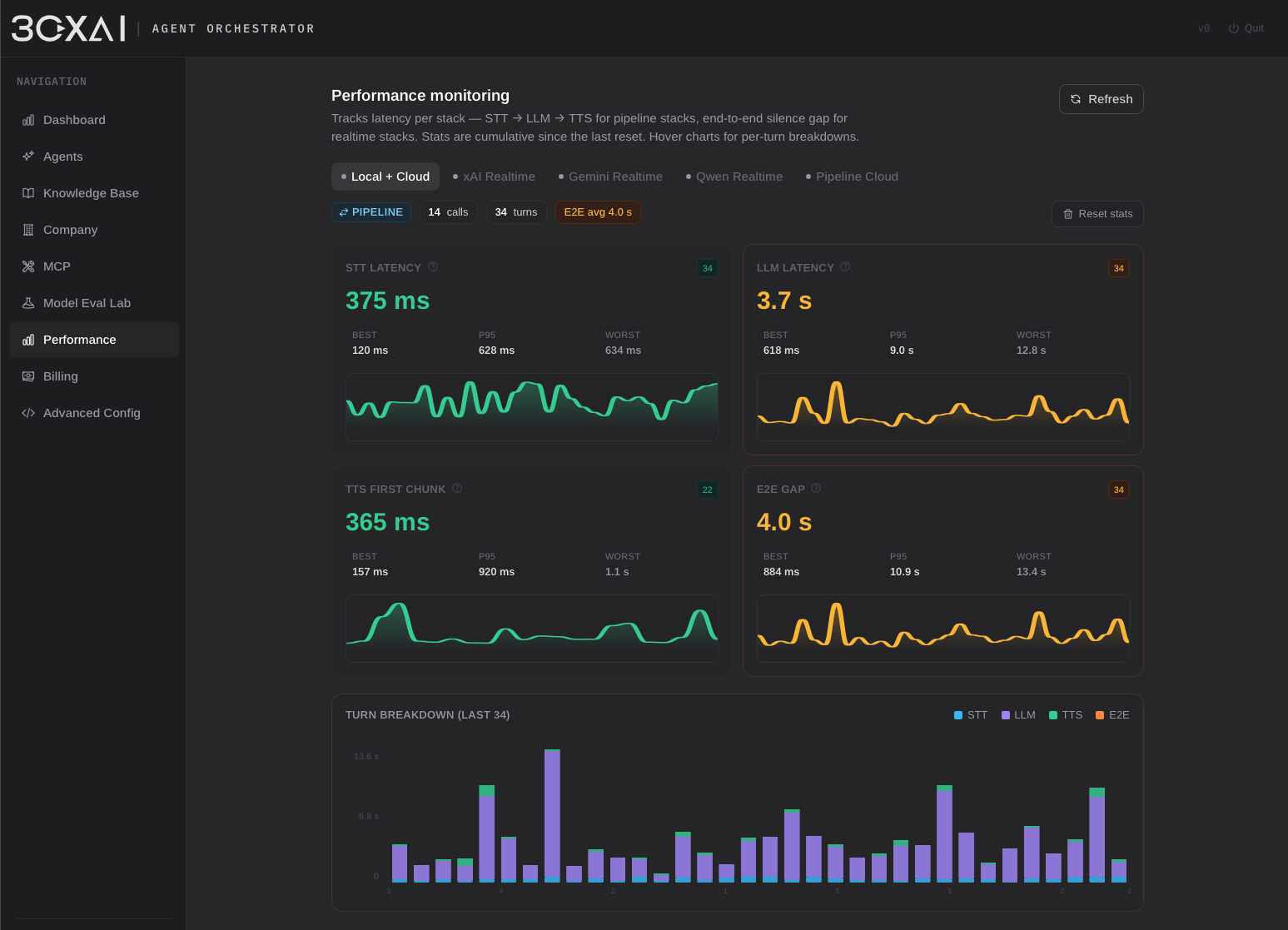
Pipeline mode 将对话拆分为独立的 STT → LLM → TTS 阶段。每个组件可单独配置,通过 cloud provider 或 self-hosted 服务部署。云端部署支持 OpenRouter、TogetherAI、Hugging Face、Grok 等 OpenAI-compatible provider;本地部署可使用 Ollama、自定义 Python 服务,或任何暴露 OpenAI-compatible 接口的 endpoint。完全支持混合架构 — 例如本地语音处理结合云端 reasoning 模型。
为最大化 provider 兼容性,pipeline runtime 基于 OpenAI-compatible API 构建,并在传统非流式 speech 服务之上实现 pseudo-streaming 层。这使广泛的云端与 self-hosted STT/TTS 方案能参与近 realtime 对话,同时保持统一集成模型。
Voice stack 可通过可选处理模块增强。平台目前支持使用 Silero VAD(ONNX Runtime)的 neural Voice Activity Detection,作为传统 amplitude-based 检测的替代,改善语音分段、打断处理与转写质量。音频处理作为独立层实现,可在不影响 surrounding runtime 架构的情况下引入更多服务。
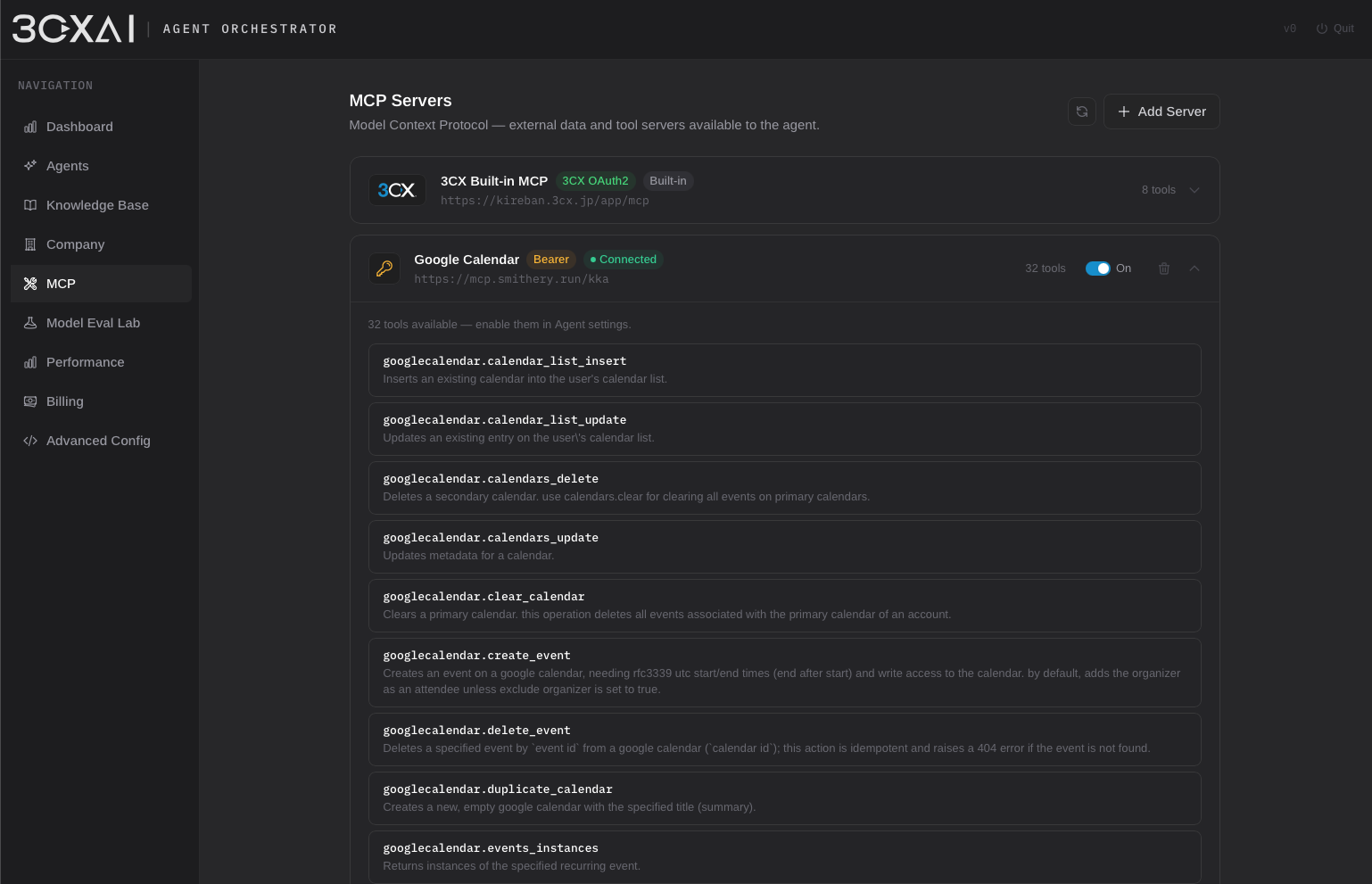
平台通过 Call Control API 与 3CX 集成以处理实时通话,并以内置 3CX MCP server 作为主要 tool 执行层。联系人查找、分机发现、呼叫转接与路由等核心能力通过 MCP tools 暴露给 agent。电话簿搜索受益于 3CX 的 fuzzy linguistic matching,有助于弥补 voice 交互中的语音识别误差。
Native streaming 支持计划在后续版本推出,作为当前 OpenAI-compatible pipeline 之外的替代执行路径,在保留相同 runtime 抽象与 agent 配置模型的同时,直接集成 streaming-first provider 与 self-hosted 服务。